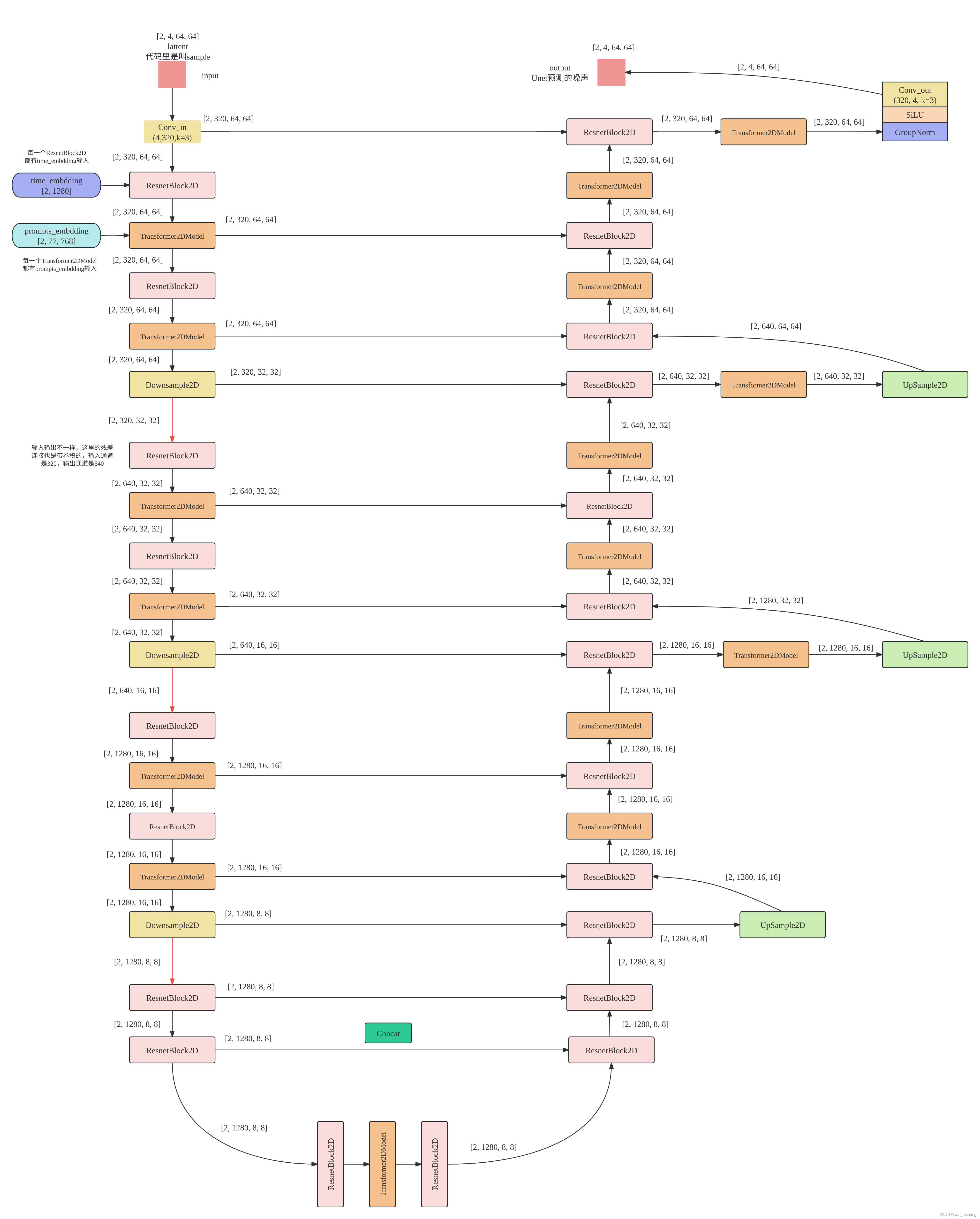
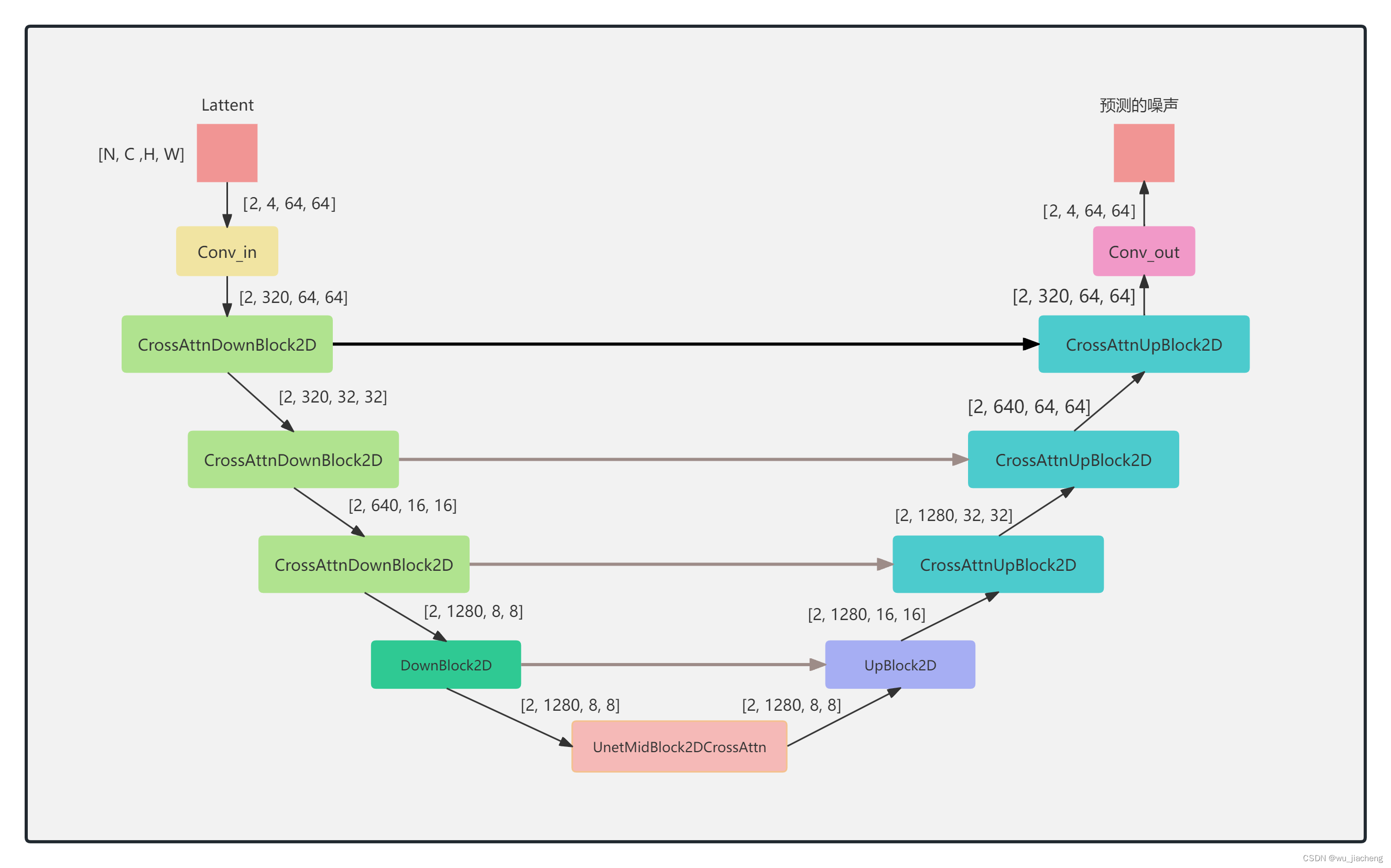
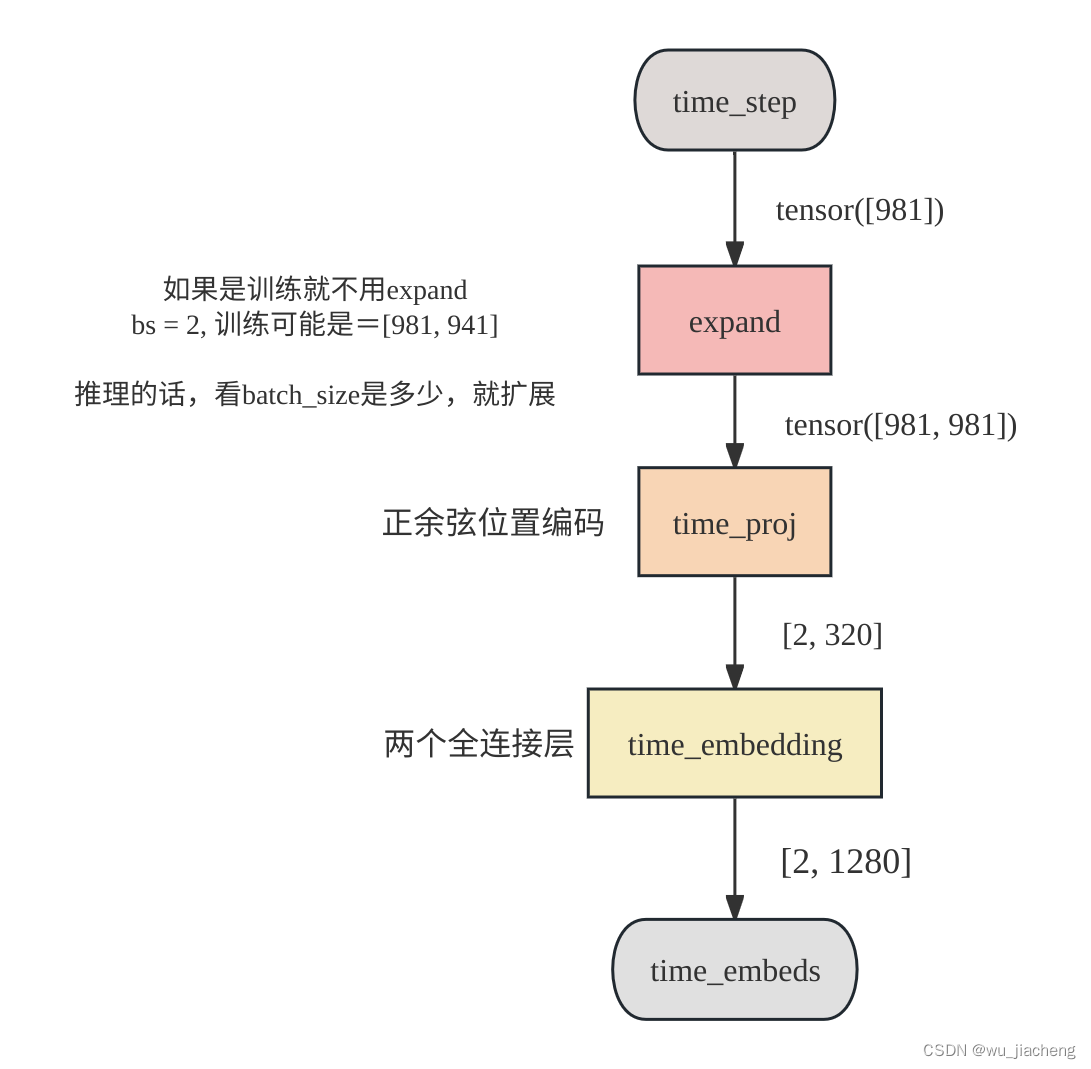
Drawing software: ProcessOn, the following pictures can be saved for high-definition viewing
Responsible for predicting noise
Each ResnetBlock2D has two inputs
One is the output latent from the previous layer,
Another output from the time step encoding module time_embeds ( shape = [2, 1280], omitted below, the default [2, 1280] is the shape of tersor)
Each Transformer2DModel input has two