
https://towardsdatascience.com/ai-accelerators-machine-learning-algorithms-and-their-co-design-and-evolution-2676efd47179
Called "single" because it uses a single set of 32 bits (in the IEEE 754 standard) to represent a floating-point number.
associative_scan

https://www.youtube.com/watch?app=desktop&v=OO3o14cINbo
Intercepts the execution of your Python code (PEP 523) and transforms it into FX intermediate representation (IR), and stores it in a special data structure called FX Graph

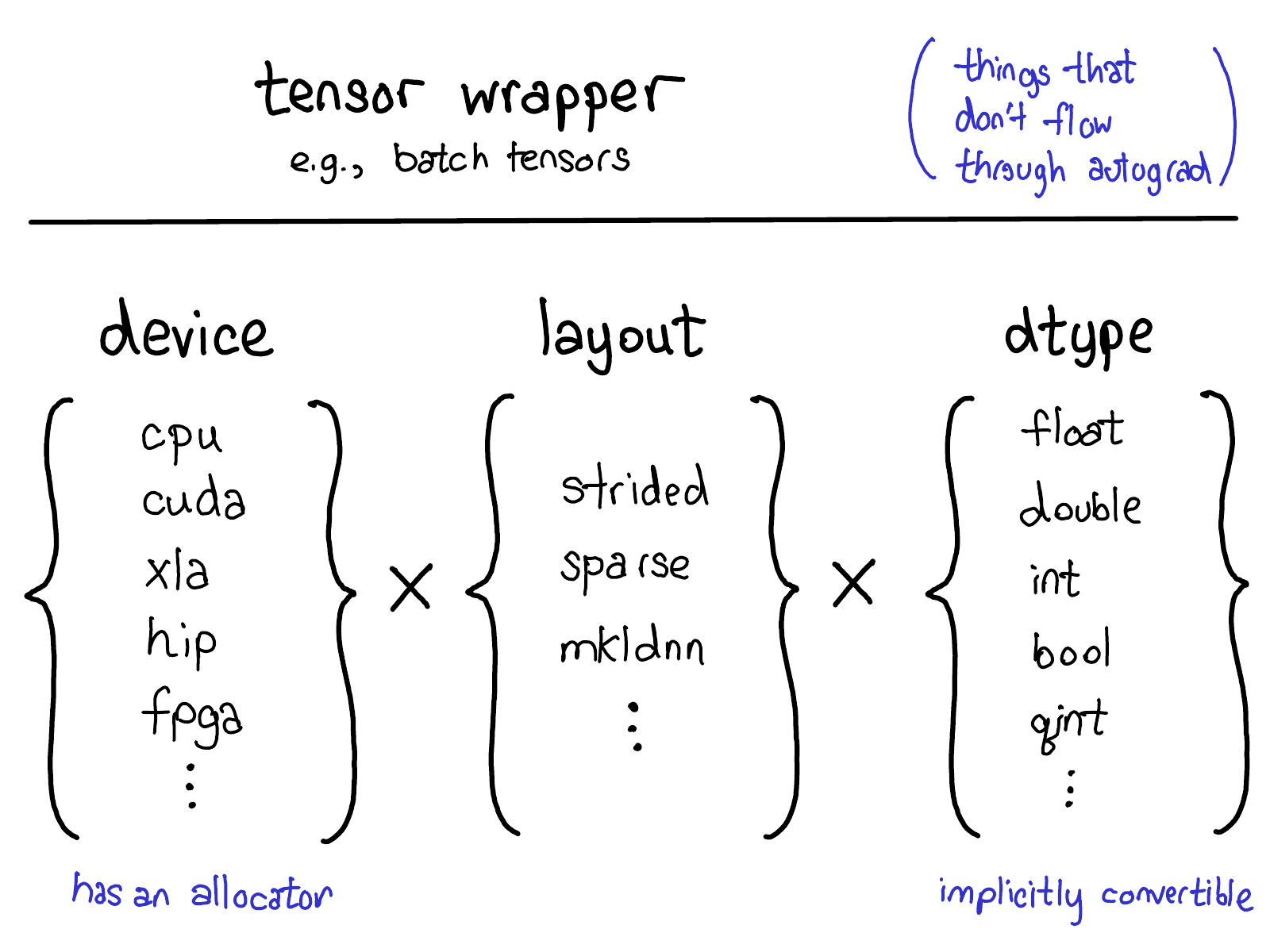
ATen IR > Core ATen IR > Prism IR
a list of operators supported by the ATen library

tensor.is_contiguous()
view(): Does NOT make a copy of the original tensor. It changes the dimensional interpretation (striding) on the original data. In other words, it uses the same chunk of data with the original tensor, so it ONLY works with contiguous data.reshape(): Returns a view while possible (i.e., when the data is contiguous). If not (i.e., the data is not contiguous), then it copies the data into a contiguous data chunk, and as a copy, it would take up memory space, and also the change in the new tensor would not affect the value in the original tensor.

https://medium.com/analytics-vidhya/pytorch-contiguous-vs-non-contiguous-tensor-view-understanding-view-reshape-73e10cdfa0dd
Stride (one of the tensor representations)

https://medium.com/analytics-vidhya/pytorch-contiguous-vs-non-contiguous-tensor-view-understanding-view-reshape-73e10cdfa0dd

Tensor Representation

http://blog.ezyang.com/img/pytorch-internals

FPGA Field-Programmable Gate Array
.png)
https://towardsdatascience.com/ai-accelerators-machine-learning-algorithms-and-their-co-design-and-evolution-2676efd47179
GPU

Event
synchronization markers that can be used to monitor the device's progress, to accurately measure timing, and to synchronize CUDA streams.
Stream
A sequence of operations that execute in issue order on the GPU
CUDA Core
Can execute instructions from threads within a warp in parallel
A single CUDA core executes a single thread at a time
Streaming Multiprocessors
A GPU consists of several SMs
Within each SM, threads are grouped into warps (32 threads in NVIDIA GPUs)

https://medium.com/@smallfishbigsea/basic-concepts-in-gpu-computing-3388710e9239
sycnhronize
Waits for all kernels in all streams on a CUDA device to complete.
CUDA Concurrency

https://developer.download.nvidia.com/CUDA/training/StreamsAndConcurrencyWebinar.pdf

Malloc
Memory allocation
global is a specifier indicating that the function is a CUDA kernel that can be called from the host (CPU) and executed on the device (GPU).
restrict
tell the compiler that a pointer is the only reference, through any path, to the object it points to for the lifetime of the pointer, which allows the compiler to generate more optimized code (e.g. loop vectorization, parallelization**)**
blockDim
the dimension of each block, the number of threads per block a thread block may contain up to 1024 threads.
Grid (collection of blocks)

https://nyu-cds.github.io/python-gpu/02-cuda/

https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html


Warp

https://medium.com/@smallfishbigsea/basic-concepts-in-gpu-computing-3388710e9239
Multi-node communication primitives

Rank: ith GPU
AllReduce = All-to-all + reduce

https://spcl.inf.ethz.ch/Teaching/2019-dphpc/lectures/lecture11-nns.pdf
Broadcast

https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html
Reduce
AllGather = All-to-all + gather
ReduceScatter = Reduce + Scatter (distributes equal portions of it to all processes)
{kind=link}