
LLM (Large Language Models) Serving quickly became an important workload. The efficacy of operators within Transformers – namely GEMM, Self-Attention, GEMV, and elementwise computations are critical to the overall performance of LLM serving. While optimization efforts have extensively targeted GEMM and GEMV, there is a lack of performance studies focused on Self-Attention in the context of LLM serving. In this blog post, we break Self-Attention down into three stages: prefill, decode, and append; analyze the performance bottleneck of Self-Attention on both single-request and batching scenarios in these three stages; and propose a solution to tackle these challenges. These ideas have been integrated into FlashInfer, an open-source library for accelerating LLM serving released under Apache 2.0 license.
FlashInfer has been developed by researchers from the University of Washington, Carnegie Mellon University, and OctoAI since summer 2023. FlashInfer provides PyTorch APIs for quick prototyping, and a dependency-free, header-only C++ APIs for integration with LLM serving systems. Compared to existing libraries, FlashInfer has several unique advantages:
FlashInfer has been adopted by LLM serving systems such as MLC-LLM (for its CUDA backend), Punica and sglang. We welcome wider adoption and contribution from the community. Please join our discussion forum or creating an issue to leave your feedback and suggestions.
There are three generic stages in LLM serving: prefill, decode and append. During the prefill stage, attention computation occurs between the KV-Cache and all queries. In the decode stage, the model generates tokens one at a time, computing attention only between the KV-Cache and a single query. In the append stage, attention is computed between the KV-Cache and queries of the appended tokens. append attention is also useful in speculative decoding: the draft model suggests a sequence of tokens and the larger model decides whether to accept these suggestions. During the attention stage, proposed tokens are added to the KV-Cache, and the large model calculates attention between the KV-Cache and the proposed tokens.
The crucial factor affecting the efficiency of attention computation is the length of the query (lq), determining whether the operation is compute-bound or IO-bound. The operational intensity (number of operations per byte of memory traffic) for attention computation is expressed as O(11/lq+1/lkv), where lkv represents the length of the KV-Cache. During the decode stage, where lq is consistently 1, the operational intensity is close to O(1), making the operator entirely IO-bound. In the append/prefill stages, the attention operational intensity is approximately O(lq), leading to compute-bound scenarios when lq is substantial.
The diagram illustrates the attention computation process in the prefill, append, and decode stages:
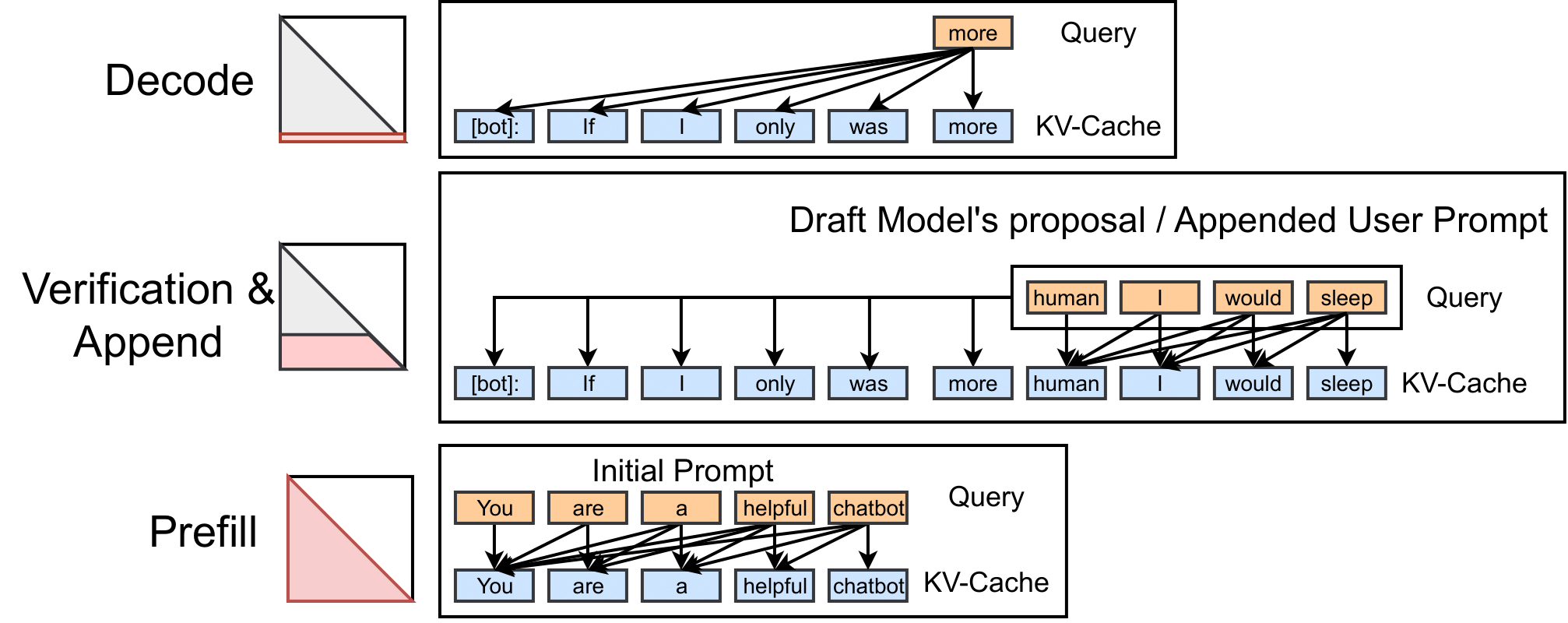
Attention in LLMs
Figure 1: Decode attention fills one row of the attention map at a time, prefill attention fills the entire attention map (under the causal mask), and the append attention fills the trapezoid region.
The figure below shows the roofline model of the three stages of attention computations. Decode attention performance is always underneath the peak bandwidth ceiling (bounded by peak memory bandwidth in GPU), and thus is IO-bound. Prefill attention has high operational intensity and is under the peak compute performance ceiling (bounded by peak floating point performance). Append attention is IO-bound when the query length is small, and compute-bound when the query length is large.

Roofline of Attention Operators
Figure 2. Roofline model of attention operators in LLM Serving, data from A100 PCIe 80GB.
There two common ways to serve LLM models: batching and single request. Batching groups several user requests together and process them in parallel to improve the throughput, however, the operational intensity of attention kernels is irrelevant to batch size 1, and batch decoding attention still has operational intensity of O(1).